ZileWatch Infrastructure Series -- Part 1

Building the API and Aggregation Engines (Technical Deep Dive)
ZileWatch is a React Native application powered by a custom-built backend API that acts as the core intelligence layer of the platform.
This document expands into a deeper technical explanation of how the backend aggregation engines are structured, optimized, and scaled.
🏗 High-Level Architecture
ZileWatch consists of:
- React Native Client
- Node.js + Express API Layer
- Aggregation Engines
- Caching Layer
- Provider Adapter Modules
Request Flow:
Client → API Gateway → Aggregation Engine → Provider Adapters → Normalized Response → Cache → Client
🧠 Core Backend Architecture
1️⃣ Modular Folder Structure
Example backend structure:
src/
├── controllers/
├── routes/
├── services/
│ ├── movie.engine.ts
│ ├── provider.adapter.ts
│ └── cache.service.ts
├── utils/
└── middleware/
Each provider is isolated to prevent system-wide failure if one source breaks.
⚙️ Aggregation Engine Internals
Engine Pipeline
- Validate Request
- Normalize Metadata
- Check Cache
- Execute Parallel Provider Queries
- Validate Stream URLs
- Normalize Output
- Cache Response
- Return Response
Provider Abstraction Pattern
class ProviderAdapter {
async search(title) {}
async getDetails(id) {}
async extractSources(pageUrl) {}
}
Each provider implements the same interface.
This ensures:
- Pluggable architecture
- Automatic fallback
- Horizontal scalability
- Maintainable codebase
🚀 Concurrency & Performance
Parallel Execution
Providers are executed using Promise.all():
const results = await Promise.all(providers.map(p => p.extractSources(url)));
This significantly reduces response time compared to sequential execution.
Caching Strategy
- In-memory cache (Redis-ready)
- TTL-based expiration
- Hot-content prioritization
- Cache invalidation hooks
Example:
cache.set(key, data, { ttl: 3600 });
🔍 Stream Validation Layer
Before returning a stream:
- HEAD request verification
- Expiry timestamp validation
- Content-type confirmation
- Dead-link filtering
This ensures frontend stability and prevents broken playback.
🛡 Error Handling & Resilience
- Try/Catch isolation per provider
- Graceful degradation
- Structured logging
- Automatic provider blacklist if repeated failures detected
Actual Implementation
Movies Scraping Engine
For the Movies Scraping Engine we use different sources to get the data, we use sources such as goojara, flixer and vidsrc we also extract data from video-hosting-sites such as doodstream and lulustream the Scraping Engine is structured in a way that allows us to easily add new sources and endpoints as needed.
For now we will focus on one source which is goojara, we use goojara to get the video sources for movies, we use Cheerio to scrape the data from goojara and extract the video sources, we also use caching and other optimization techniques to ensure that the data is provided to the API in a way that is fast and efficient.
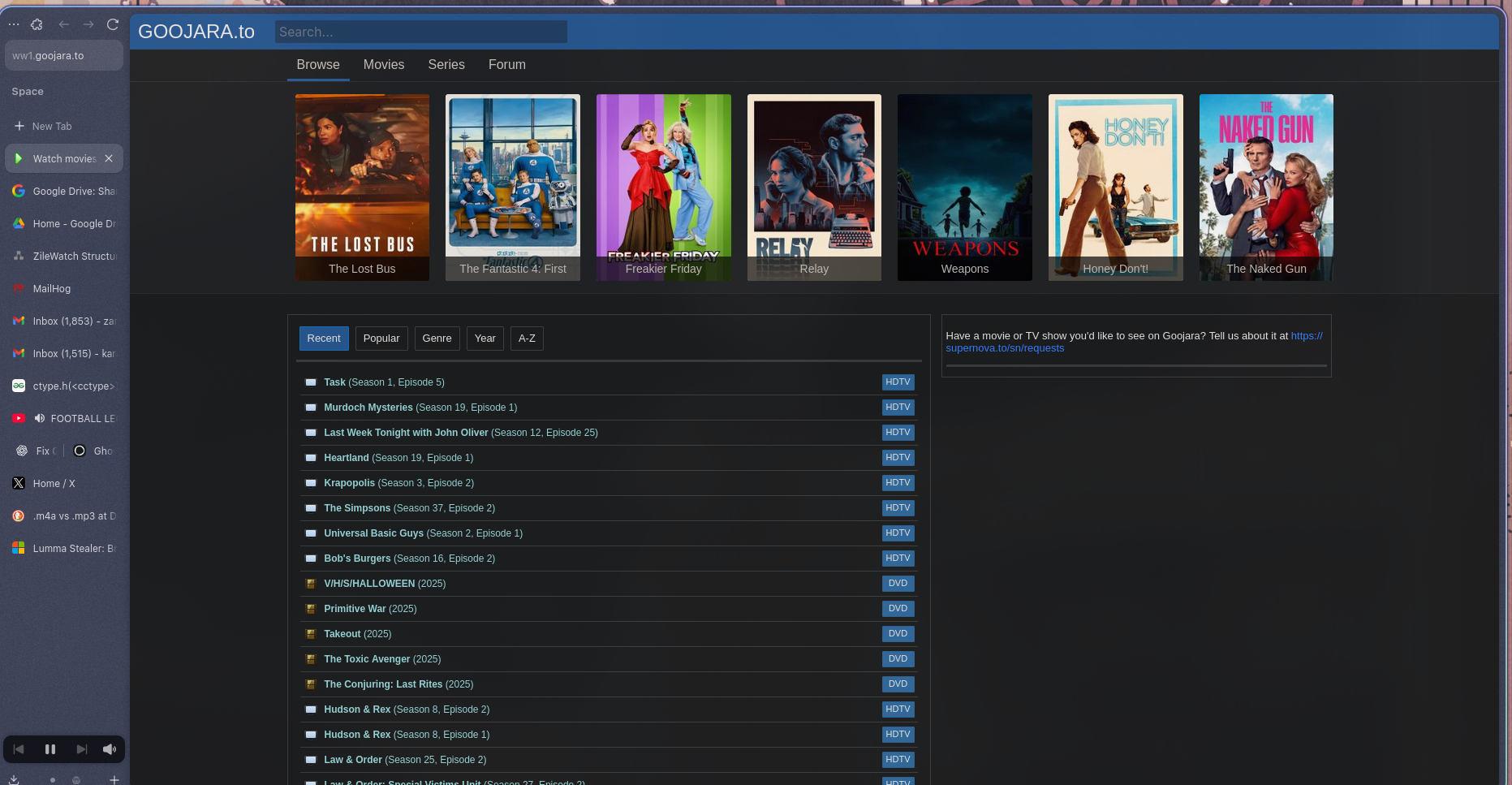
The Above Diagram shows the landing page for the goojara website, this website has been the around for a decade now one the best sites to get Movies and Tv-shows and the best at getting the latest Tv Episodes that are release on the same day, this site uses anti-debug to prevent users from accessing the network tools to prevent scraping,thus we had to use alternative site which acts as probably a mirror for goojara and does not have the same anti-debug techniques, this site is called Levida and it has the same structure as goojara and we can easily scrape it using Cheerio.
We also used a tool that allows the access to the network tools which is executed by script and it is called puppeteer, this tool allows us to access the network tools and scrape the data from goojara without being detected, we use puppeteer to access the network tools and extract the video sources from goojara.
Accessing the network tools allows us to put our detective hat on and observe how the website behaves when we access it, we can see how the website loads the video sources and how it interacts with the user, this allows us to understand how the website works and how we can scrape it without being detected.
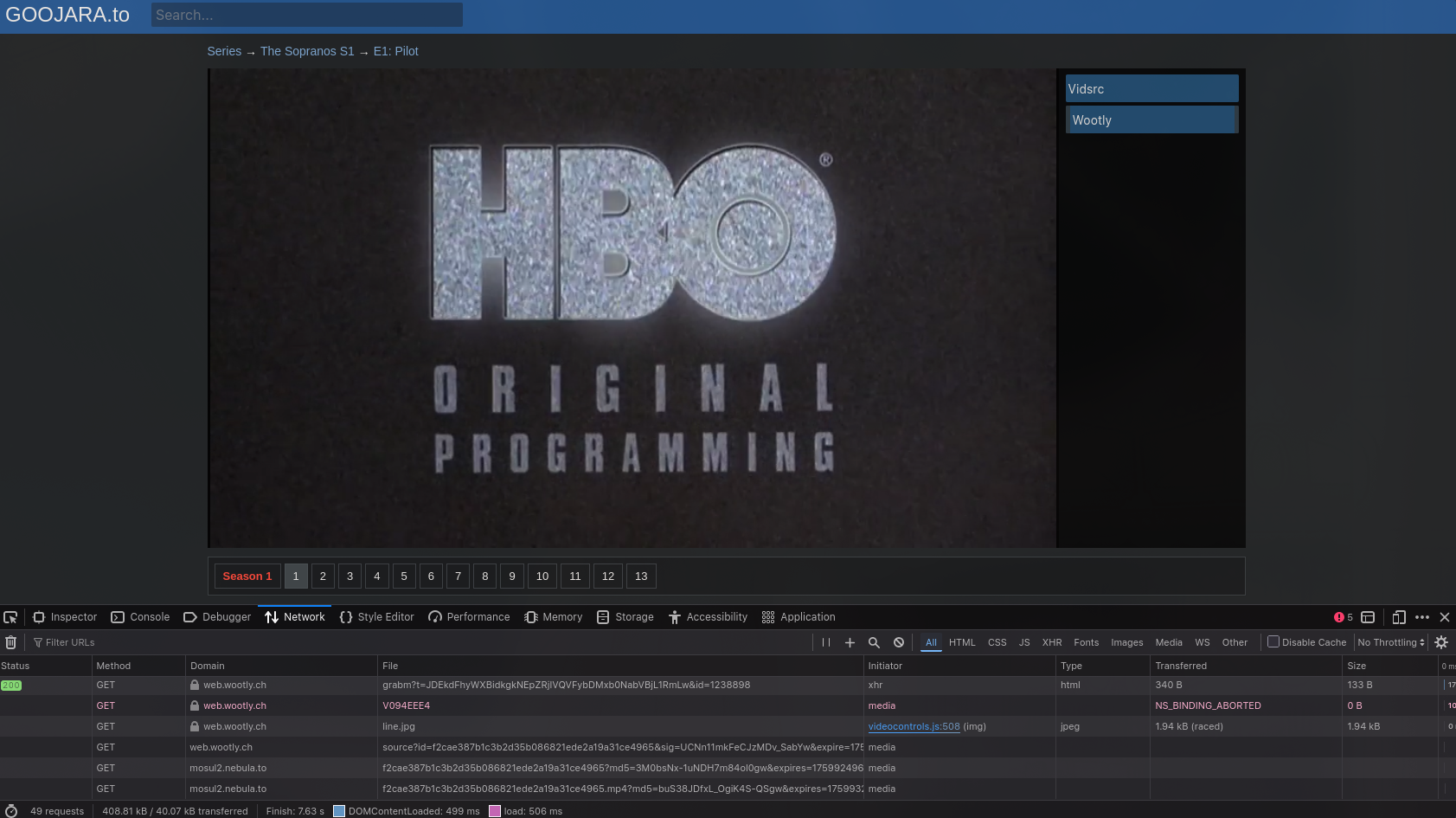
As we can see from the picture above, we did our investigation by observing on how the website gives the .mp4 source we used a well known Tv-Show Called The Sopranos and we observed that the website gives us the .mp4 source in the network tools, we also observed that the website uses a lot of anti-debug techniques to prevent us from accessing the network tools, but with puppeteer we were able to access the network tools and extract the video sources from goojara without being detected.

From the Network Logs we are able to discover interesting things:
https://web.wootly.ch/source?id=33c6dd7acd5992a31da149ac2ef52547a19fbc8b&sig=-0aU16aoQJrT3hGlSMDceA&expire=1771102306&ofs=12&usr=141392
This url gives as a response that is the sweet spot it basically shows the video URL with .mp4 format our EndGoal
https://turin2.nebula.to/33c6dd7acd5992a31da149ac2ef52547a19fbc8b.mp4?md5=7gvrb5qY668f9PmTZt0GpQ&expires=1771109511&fn=33c6dd7acd5992a31da149ac2ef52547a19fbc8b.mp4
And Wolah!! we have found the actual video source that can be used by any video media player i.e MPV or VLC
📈 Scaling Strategy
Designed for:
- Docker deployment
- Horizontal scaling
- Reverse proxy integration
- CDN-ready architecture
- Stateless API nodes
Future improvements:
- Distributed caching
- Queue-based provider execution
- Observability dashboards
- Auto-scaling clusters
📊 Response Standardization
All responses follow this format:
{
"title": "Movie Title",
"year": 2026,
"sources": [
{
"quality": "1080p",
"url": "stream-url",
"provider": "provider-name"
}
]
}
Frontend never depends on provider-specific logic.
🔮 What's Next?
Part 2 will cover:
- Live Sports ingestion pipeline
- HLS handling at scale
- Real-time channel switching
- Adaptive bitrate considerations
📲 Download ZileWatch
👉 Android APK:
Download Here
👉 Official Website:
Visit Website
🧑💻 Author
Engineered by Stephen Zarachii
GitHub: https://github.com/zilezarach
⭐ Stay tuned for Part 2.